
Representing variability for EFSM model generation
The goal of this work was to use variability modeling in the semi-automatic generation of EFSMs. Variabilities were identified to facilitate the generation of models used for developing and testing. To exemplify the entire process, we show a sample text (Figure 1), with some characteristics which are often found in standard documents.
Figure 1 - Text fragment to illustrate the proposed methodology
EFSM model generation
In the generation of the EFSM models, presented in Figure 2, there are two actors involved: the expert analyst, who processes the document using NLP tools; and the expert user, who develops the software for a specific application. Figure 3 shows the process diagram for State Machine Generation. The entire process has seven steps, which are described next.
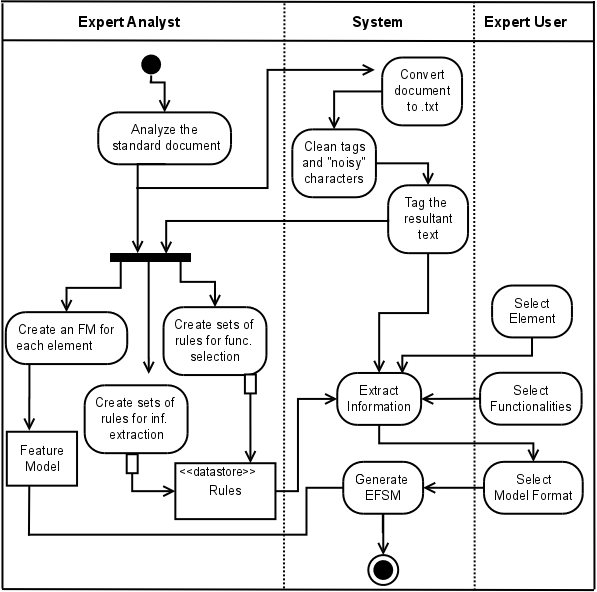
Figure 2 - Activity Diagram for State Machine Generation
Step1 - Semi-automated analysis of the standard document
The semi-automated analysis of the standard document comprises a set of activities performed by the expert analyst (Figure 2). The process initiates with the selection of the standard document to be processed (Figure 3). The document must be in plain text format (.txt) to be processed by the NLP tools. If the text is available in a different format, it must be converted to .txt. The plain text standard document is then processed by a word frequency counter tool, and the results are used in the analysis of the text. This analysis helps to identify structural patterns in the sentences. Stop words, i.e., words that have a high frequency but no semantic meaning [4], are not taken into account in the analysis. An example of an identified pattern is: most sentences initiating with the word "if" present a condition for the execution of an action, as it can be noticed in the sentence "If no transferred packet was lost, a success message must be transmitted to the sender".
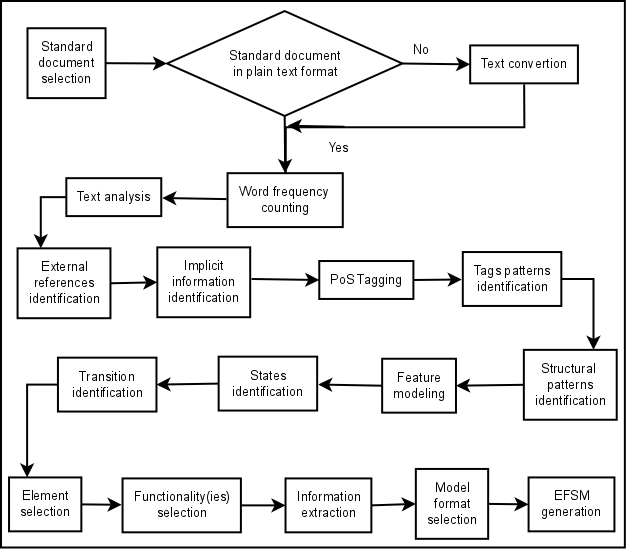
Figure 3 - Process Diagram for State Machine Generation.
Step 2 - Reading the text
After finding patterns in the sentences, the next process is the careful manual reading of the standard document to identify references to other documents, or to a different section or chapter of the same document (Figure 3 - "External references identification" process). This information is marked for future processing.
The next process is to identify implicit information, i.e, information represented in tables or figures that are not explicit in the text, and that are related to the described service (Figure 3 - "Implicit information identification" process). This information must also be marked and processed to be used in a later stage. In the proposed methodology, information described in different chapters/sections, or as figures or tables, is manually extracted and stored in a database for EFSM generation. This fact can be observed in Figure 2, section 3.4: the dependency relation is not explicit in the text, and must be manually extracted and stored in a database to be used during model generation.
Step 3 - Reading the service description
Text is pre-processed using a PoS Tagger (Figure 3 - "PoS Tagging" process). Each category attributed to a word is a tag that can be used to help the expert analyst in the extraction process. In Figure 4, we can observe sequences of tags. In the underlined text segments, the sequence "noun (tags initiated by NN) preposition (tag IN) adjectives (tag JJ) noun (tags initiated by NN) noun (tags initiated by NN)" is recurrent and can be used to identify sets of information that must be extracted and used in later stages. The process of finding patterns in the sequences of tags is represented, in Figure 3, by the "Tags patterns identification" process.

Figure 4 - Text segments for tag pattern identification
In addition to the categories, the structural pattern identified in the document can also be used during information extraction. The identification of structural patterns is the next process represented in Figure 3 - "Structural patterns identification". An example of a structural pattern can be found in Figure 1, section 3.3.1. There is a description of a functionality, followed by a parenthesis, two numbers separated by a comma, and another parenthesis. The first number is the identification of the functionality, and the second indicates if it is a mandatory (number 1), or an optional functionality (number 2). The pattern - "description parenthesis number comma number parenthesis" can be used in the extraction process to help the identification of information.
After the analysis, the expert analyst must identify mandatory and optional functionalities described in the text. These functionalities must be represented in a feature model, which is used to guide the selection of services and functionalities in a later stage of the processing (Figure 3 - "Feature modeling").
The first three steps are represented in Figure 2 by the activities "Analyzing the standard document", "Converting the document to .txt", "Text cleaning", which eliminates markup tags added during text conversion, and ’noisy’ characters", "Tagging the resultant text", and "Creating an FM for each service".
Step 4 - Identification of states and transitions
The process continues with the identification of states, which relies on the location of the information, e.g., the section of the document where the information is described, and on the sequence of the tags (Figure 3). In Figure 1, we can see that states are located in the "Concepts" section, identified by the number of the chapter, and by the number of the section (3.2). We can also observe that the description of the stages starts with a noun (tags initiated with NN), followed by "of" plus and adjective, and finished with a noun. This pattern may be identified in Figure 4, in the underlined text segments.
The tasks to identify transitions are very similar to those for state identification, and described in Figure 3 by "Transition identification". A transition is composed of events, actions and conditions, also known as guards. The identification of each transition component can follow a set of rules and patterns.
The
identification of conditions and actions, for example, is based on
the keyword "if". In Figure 1 we can observe two different
situations: the if-clause at the beginning of the sentence (Figure1,
section 3.2.b - " If a field value is out of range, a failure
report must be generated."), and the if-clause at the end of the
sentence (Figure1, section 3.2.a - "An error shall occur if any
mandatory field is not filled."). In the first situation, the text
segment between the conjunction and the comma is a condition ("a
field value is out of range"), and the text segment after the comma
is an action (" failure report must be generated").
In the second situation, the action is the text segment until the
conjunction ("An error shall occur") and the condition is the
text segment after the conjunction ("any mandatory field is not filled.").
Patterns are used to create sets of rules to extract information from the
standard document. The set of rules must cover the entire description
of a service present in the standard document. It is possible that
each service may need a specific set of rules, because the
methodology is highly dependent on the text structure and on the
writing style. Activities involved in states and transitions
identification are represented, in Figure 2, by the activities
"Create sets of rules for func. selection", and "Create sets of
rules for inf. Extraction".
Step 5 - Selection of the service and functionalities to be modeled
This is the first activity performed by the expert user, who is using the requirements described in the standard document for the development of a new system. He/she must select the service that needs to be modeled (Figure 3 - "Service selection"). The mandatory functionalities are selected by default, but the expert user may select the optional functionalities that must be present in the model (Figure 3 - "Functionality(ies) selection").
Step 6 - Information extraction
"Information extraction" is the next task to be performed (Figure 3 - "Information extraction"). The sets of rules, created during Step 4, are applied in the standard document to extract information about a specific service, selected by the expert user in Step 5. The whole information about the selected service is recovered. After the extraction process is completed, the necessary information to represent only the functionalities selected in Step 5 is filtered and sent to the next step, that is, generation of EFSM.
Step 7 - Generation of the EFSM
In the last step of the entire process, the expert user must select the model format (Figure 3 - "Model format selection"). The text format is generated by default, but the user may request the generation in graphical format too. The last activity is the generation of the model (Figure 3 - "EFSM generation"). The extracted information filtered according to the selection made by the expert user are used to generate the EFSM. We have implemented a prototype to validate the proposed approach.
The last three steps are represented in Figure 2 by the activities "Extract Information", "Select Service", "Select Functionalities", "Select Model Format", and "Generate EFSM".
Working Example
To illustrate our approach, we have applied it to the PUS document [2]. We developed a prototype to extract the necessary information, and to generate different models for the same service, taking into account the commonalities and variabilities of the service. The PUS document describes a set of 16 services to support functionalities for spacecraft monitoring, but there are no mandatory services for a given mission. Each service is described with a minimum capability set, that must be always included in every implementation of the service, and additional capability sets that may be optionally implemented [2]. In addition to the variability, the document also defines other important requirements that must be considered in the implementation of each service, and which may appear in different sections of the PUS document.
We show an example of an instantiation of the feature model for the generation of a state machine for the Telecommand Verification Service (TVS). This example was executed using the prototype especially developed for the task. Concerning document processing, the following features were selected: standard document version: V1, corresponding to the version from 30 January, 2003; Text converter: C1; POS Tagger: T1; Service: TVS; Minimum Capability: Capability Group 1, corresponding to Acceptance of the telecommand; Additional Capabilities: Capability Group 2, corresponding to the Progress of the Execution of the telecommand; Edit Information: No edition; Model Format: text.
With this configuration, an EFSM in text format is generated, and shown here in a tabular form (Table 1). The first column shows the state names, extracted from the PUS document. The second and third columns are names used to identify input and output events for each state. These names were semi-automatically extracted from the document during the information extraction phase, presented in Figure 3. This simple example shows the state machines generated to represent the normal behavior of the Telecommand Verification Service.
Table 1: Output from the State Machine Generation System
|
State |
Input Event |
Output event |
|
withoutTC |
TC |
TC |
|
Acceptance of telecommand |
TC |
AcceptanceOK |
|
Progress of execution |
AcceptanceOK |
ProgressOK |
Figures 5 and 6 show the execution of the working example with the developed prototype. Figure 5 shows the selection of additional capabilities, and Figure 6 the information which represents normal behavior in the state machine generation.
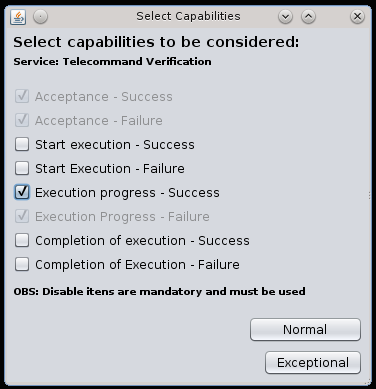
Figure 5- Selection of additional capabilities in the prototype tool.
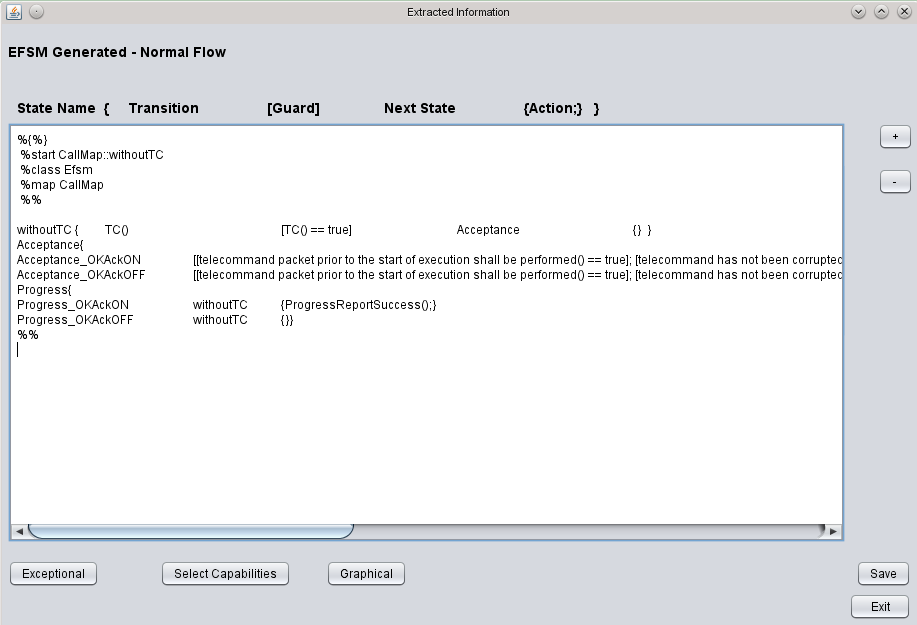
Figure 6 - Information to represent normal behavior in the state machine generation.
Conditions and other additional information for the EFSM are extracted and stored in a database, and added to the state machine during the final model generation, in the notation selected by the user.
This working example helps to answer the following research question, presented in Section 1: Can these models be generated semi-automatically? Yes, they can, with NLP tools and techniques used to extract information from the standard document to generate EFSM models. The last question posed in Section 1 is: How can we manage the large number of different models that can be generated, considering the combination of mandatory and optional requirements? The product line approach helps to deal with the different models which may be generated for the same service, considering the possible combinations between mandatory and optional features. The prototype controls the configuration options presented in the proposed FM, and the possible combinations are generated in a controlled way, avoiding invalid feature combination.
The evaluation of the generated EFSMs was performed in two ways: 1) A comparison of the automatically generated EFSM with a manually created EFSM, available in Véras [6]; 2) A model checking using the DiVinE Model Checker [1].
The first comparison showed some differences between the resulting state machines. The semi-automatically generated state machine (Figure 7) starts in the state "Acceptance", while the manually created state machine(Figure 8) starts in the state "Without TC". Although the state "WithoutTC" is not described in the text, the expert users understand that the initial state of a service must always be "empty". In this context, this initial state was introduced in the generated state machines as a default state. Another difference is the "Checking TC" state, presented in Figure 8. It is as a guard condition in the automatically generated state machine. These conditions are text segments in natural language, which were not presented in Figure 7 due to space limitations. Self loops are another difference between the models (Figure 8 - T7, T8). As already mentioned in [3], self loops are very difficult to be treated. In the proposed approach if this information is not explicit in the text, the identification of self loops could be highly dependent on human interpretation, or it would require semantic analysis, which is beyond the capabilities of the tools used.
The last difference regards the notation used in information stored in the database, for example, the Ack field. In the manually created state machine, it is represented by curly brackets filled up with hyphens and "1". In the automatically generated state machine, this information is expressed textually ("AckON" or "AckOFF").
Despite the differences, it is possible to see that the main information about the states and transitions are the same; this is a strong indication that the automatically generated state machine is very close to that manually created.
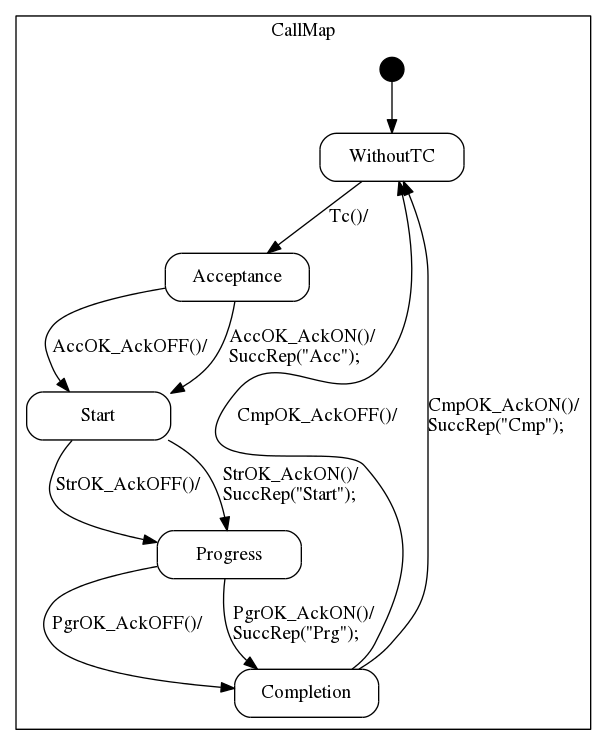
Figure 7 - Semi-automatically generated EFSM
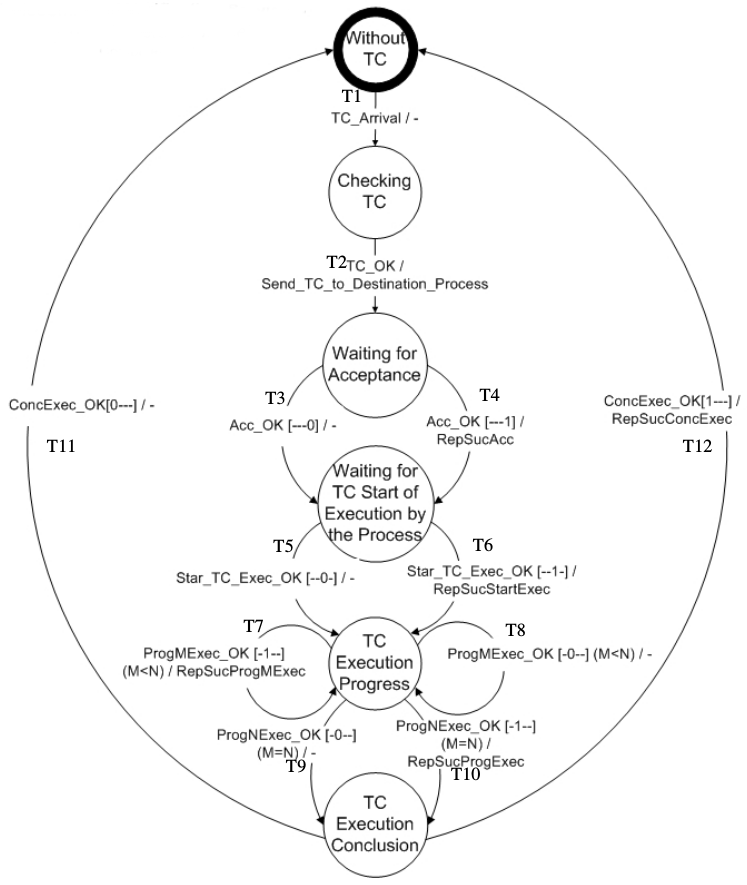
Figure 8 - Manually created EFSM. From [6]
Feature Model Validation
The feature model presented in Figure 9 was validated within the FaMa FW [5] tool, which represents variability via feature models. FaMa FW performs many analysis operations on an FM, for example, checking if the FM has at least one valid product, computing all valid products for a given FM, and the variability degree of the FM.
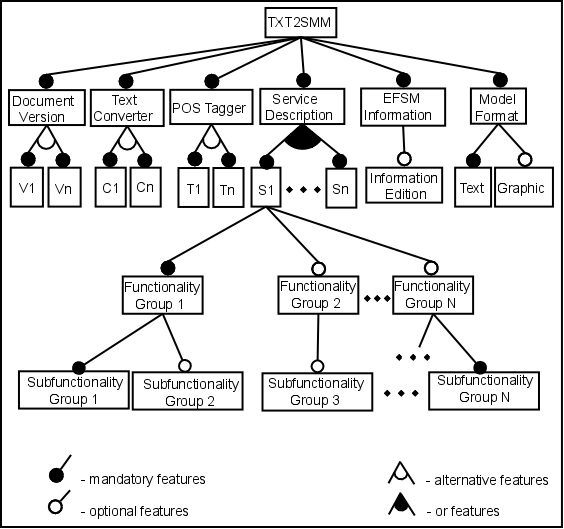
Figure 9- Feature diagram for the txt2smm system.
FaMa FW can be used in a shell front-end, or integrated to other applications. In this work, we have used the shell front-end. All available operations in the command line interface were applied, and no errors were found (Figure 10). For instance, the Telecommand Verification Service (TVS), affords two document versions, two converter tools, two PoS taggers, the different combinations of capabilities from TVS, the possibility of editing information, and two model notations to represent the EFSM. Choices between the several alternatives multiply to give 256 descriptions of new products. The number gets even larger if we consider that the PUS document describes 16 services.
Some invalid products were tested and the results are presented in (Figure 10). Invalid products are rejected, and the tool explains why the model is invalid. FaMa FW [5] identifies the problem in the product being specified, and explains the encountered error(s). The tool also explains what is wrong during feature model validation.
The prototype avoids the selection of invalid combinations, for example, automatically selecting mandatory features from a selected service by the expert user, or automatically selecting/deselecting features related to an optional, or alternative feature selected by the expert user. Regarding the selection used in the working example for the Document Version, the PoS tagger, the text converter and the selected service, there are 8 different possible combinations of additional capabilities for the TVS.
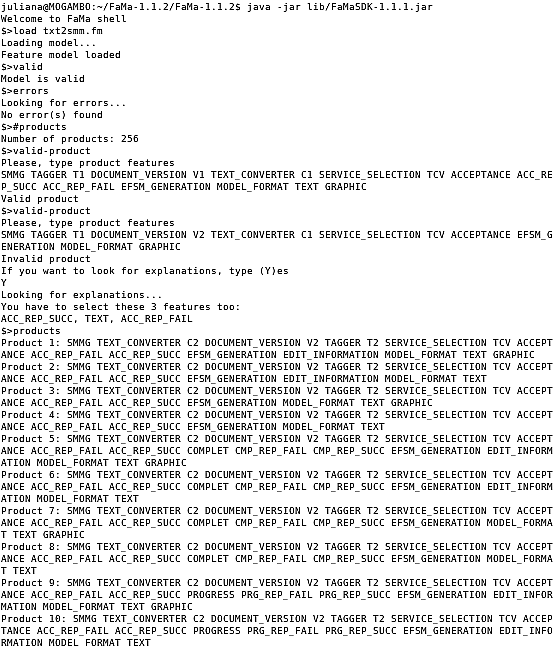
Figure 10- Results from feature model validation using FamaFW
References
[1] J. Barnat, L. Brim, V. Havel, J. Havlek, J. Kriho, M. Leno, P. Rokai, V. till, and J. Weiser. DiVinE 3.0- An Explicit-State Model Checker for Multithreaded C & C++ Programs. In Computer Aided Verification (CAV 2013), volume 8044 of LNCS, pages 863–868. Springer, 2013.
[2] ECSS. Ground systems and operations - Telemetry and telecommand packet utilization. ECSS-E-70-41A. ESA Publications Division, 2003.
[3] L. Kof. Translation of textual specifications to automata by means of discourse context modeling. In M. Glinz and P. Heymans, editors, Requirements Engineering: Foundation for Software Quality, volume 5512 of LNCS, pages 197–211. Springer Berlin Heidelberg, 2009.
[4] C. D. Manning and H. Schütze. Foundations of statistical natural language processing. MIT press, 1999.
[5] Research Group of Applied Software Engineering. FAMA-FeAture Model Analyser. http://www.isa.us.es/fama/.
[6] P. C. Véras. Benchmarking Software Requirements for Space Applications Documentation. PhD thesis, Aeronautics Institute of Technology, 2011.